 Connexion
Connexion Field-Map Inventory Analyst
| Cette application permet le traitement statistique efficace des données de tous types de projets d’inventaire forestier. Avec Inventory Analyst, les données collectées peuvent être analysées pratiquement tout de suite après la phase de terrain. Pendant tous les calculs, l’intervalle de probabilité à des niveaux prédéfinis par l’utilisateur est automatiquement calculé. Il est possible de combiner la stratification avec plusieurs classificateurs en même temps pour obtenir le maximum d’informations de vos données. Les données sont représentées sous forme de tableaux et graphiques.
Inventory Analyst est disponible en 3 versions – avec la limite de 100 et 1000 placettes et avec un nombre de placettes illimitées. FMIA permet d'effectuer les tâches suivantes : Les avantages principaux de Inventory Analyst: |
|
| Comment fonctionne Field-Map Inventory Analyst Pas à pas |
|
| Etape 1. Démarrer Field-Map Inventory Analyst et ouvrir un projet. Chaque projet Field-Map représente une série de placettes d'inventaire réparties sur le terrain d'étude (c'est-à-dire au niveau d'un IFN, un projet contient les données de tout le pays); les données n'ont pas besoin d'être converties depuis la base de données de terrain. |
|
| Etape 2. Connecter un projet Les couches et attributs du projet doivent être "connectées" à Field-Map Inventory Analyst, c'est-à-dire que l'utilisateur doit indiqué quel couche correspond à la couche arbre, la couche bois mort, etc. Ceci s'explique par le fait que l'utilisateur est libre de dévelpper son projet Field-Map selon sa propre méthodologie. |
 |
| Etape 3. Calcul des variables secondaires et dérivées utilisant les modèles et fonctions prédéfinis. Par exemple calcul des hauteurs des arbres qui n'ont pas été mesurées sur le terrain. Calcul du volume des arbres avec l'équation définie par l'utilisateur ou vavec les équations locales. |  |
| Etape 4. Post-stratification Une grille de placette d'inventaire peut être sur-imposée sur toute carte polygonale et les informations sont prises des polygones et attachées aux placettes d'inventaire. |
 |
| Etape 5. Aggrégation des données de couches spécifiées et statistique descriptive. Par exemple: résumé du bois mort par placette, calcul du volume moyen du bois mort, variance de l'échantillon, déviation et erreur standard etc. Une fois que la tâche eest définie, elle peut être utilisée répétitivement et même partagée entre plusieurs projets; le même prinicpe est applicable pour les tâches de classification, re-classification, mises à jour SQL et traitement statistique |
 |
| Etape 7. Classification des données continues dans des classes (par exemple des classes selon l'âge, diamètre etc). Les variables classifiées peuvent être re-classifiées afin de suivre différents schéma de classification, par exemple les espèces peuvent être groupées en groupes d'espèces. |
 |
| Etape 8. Re-classification Regroupement des données discrêts: par exemple grouper les arbres dans les groupes d'arbres | |
| Etape 9. Mise à jour SQL et scripts Emploi du SQL et du script défini par l'utilisateur pour la création et le calcul des variables dérivées. |  |
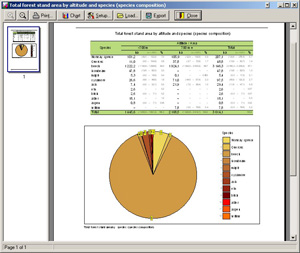
| Etape 10. Traitement statistique des données Les tâches de traitement statistique des données peuvent être formulées de manière interactive et peuvent être utilisées répétitivement. Les résultats sont présentés dans des tableaux et graphiques. Toutes les tâches peuvent être complétées par un commentaire de l'utilisateur, la description de la méthodologie et des définitions. |
 |
  |
|
Si vous souhaitez obtenir plus d'informations contactez nous.